R es un Lenguaje de Programación diseñado específicamente para análisis estadístico.
Glosario de Programación
Programación: Acción y efecto de programar.
Programar: Proceso de crear instrucciones para un computador de modo que este ejecute las instrucciones establecidas.
Lenguaje de Programación: dialecto específico utilizado para programar.
En Chile se habla español, como en R se habla en lenguaje… ¡R!
El lienzo donde el programador escribe sus instrucciones es denominado Código o Script.
Sintaxis: son las reglas del lenguaje de programación sobre cómo estructurar las palabras de este lenguaje para que sea funcional.
Dinámica de Programación
Humano escribe código,
Humano entrega código al programa (R en este caso),
Programa ejecuta las instrucciones correctamente.
Humano es feliz 😁
Dinámica Realista de Programación
Humano escribe código,
Humano entrega código al programa,
Programa lo rechaza por contener errores de escritura,
Humano entrega código corregido,
Programa vuelve a rechazar ,
Humano entrega código corregido,
Programa vuelve a rechazar ,
Humano entrega código corregido,
Programa vuelve a rechazar ,
Humano entrega código corregido,
Ejemplo de un código en R
notas <-c(5.1, 4.2, 6.3, 5.9)promedio <-mean(notas)print(paste("Nota Final en EPG3308:", promedio))if(promedio <4.0){print("¡Oh no! He reprobado el curso :( ")} else{print("Facilito el curso :) ")}
¿Qué hará este código?
¿Por qué usar R?
Es gratis.
Liviano y disponible en múltiples plataformas.
Flexibilidad para construir procesos complejos.
Rápido y eficiente en ejecutar sus tareas.
Programa de Código abierto.
Herramientas básicas y avanzadas para manipulación de datos.
Herramientas básicas y avanzadas para estadística.
Comunidad construye nuevas librerías.
Poderosas herramientas gráficas.
¿Cómo se aprende a programar en u otro lenguaje?
Aprendiendo la sintaxis y el dialecto del lenguaje de programación.
Familiarizándonos resolviendo tareas sencillas.
Resolviendo problemas interesantes.
¡Equivocándonos mil y un veces!
Corregir los errores enseña más que cien cursos
Hoy aprender a programar es más fácil que nunca
¿Por qué usar R y no Python, o Julia, u otro lenguaje?
Python requiere librerías extras para algunos procedimientos estadísticos básicos.
R dispone de métodos estadísticos avanzados:
Modelos Lineales Generalizados
Análisis de Series de Tiempo
Métodos Bayesianos
Nota
Python o Julia siguen siendo excelentes opciones para estadística clásica.
Desde R Studio, crear un nuevo código y guardarlo bajo algún nombre en alguna carpeta.
Dentro del código creado, escriba comentarios anteponiendo cada una con un símbolo #.
# !Esto es un comentario!##### ¡Esto tambien es un comentario!# Copiar desde el boton en la esqina superior derecha de este cuadro.
Escriba en el código lo que ha aprendido durante esta sesión y aquello que le causa curiosidad del curso.
Guarde el archivo y subir a Actividad Bonificada 1 en la sección de Tareas de Canvas.
EPG3308: Computación Estadística
Clase 02: Uso de R Básico
Profesor: Hernán Robledo Araya (harobledo@uc.cl) Ayudante: Josefa Silva Muñoz (josefa.silva@alumni.uc.cl)
Primer Semestre - 2025
¿Cómo se aprende a programar en u otro lenguaje?
Aprendiendo la sintaxis y el dialecto del lenguaje de programación.
Familiarizándonos resolviendo tareas sencillas.
Resolviendo problemas interesantes.
¡Equivocándonos mil y un veces!
Como ejecutar código en R
Atajo del Teclado: Control + Enter
Para código escrito en Consola tan solo presionar Enter.
R La Calculadora
R como Calculadora
Suma con + y Resta con -
1+1
[1] 2
10+20
[1] 30
-5+50
[1] 45
10-2
[1] 8
5-5
[1] 0
-1-10-100
[1] -111
R como Calculadora
Multiplicación y División
-5*6
[1] -30
3/-2
[1] -1.5
Potencias y Raíces
2**2
[1] 4
-1^2
[1] -1
2^(1/2) # Raíz cuadrada
[1] 1.414214
sqrt(-1) # NaN = Not a Number
[1] NaN
R como Calculadora
El orden en que se aplican las operaciones sigue las reglas de la matemática.
Usar paréntesis () para agrupar sus operaciones y salir de duda.
Orden:
Paréntesis
Exponenciación y raíces
Multiplicación y división (de izquierda a derecha)
Suma y resta
R como Calculadora
El orden en que se aplican las operaciones sigue las reglas de la matemática.
Usar paréntesis () para agrupar sus operaciones y salir de duda.
1+2*2
[1] 5
1+ (2*2)
[1] 5
-1*2^3
[1] -8
-1* (2^3)
[1] -8
R como Calculadora
El orden en que se aplican las operaciones sigue las reglas de la matemática.
Usar paréntesis () para agrupar sus operaciones y salir de duda.
3-2/5*5
[1] 1
3- ( (2/5) *5 )
[1] 1
-5/7+2*2
[1] 3.285714
(-5/7) + (2*2)
[1] 3.285714
¡Actividad de Cinco Minutos!
Transforme a grados Farenheit los 26 grados Celsius pronosticados para mañana.
\[F = 32 + C \times \frac{9}{5}\] 2. Si usted obtuvo un promedio de notas de laboratorios de \(3.5\), un promedio de tareas de \(4.2\), y un examen de \(4.5\), ¿aprueba el curso?
¡Actividad de Cinco Minutos!
Sea \(p\) el puntaje obtenido en una evaluación que tiene \(p_{max}\) puntos como máximo. La nota que un estudiante obtiene bajo cualquier porcentaje de exigencia \(Ex\) se calcula como sigue:
Si se obtiene un puntaje \(p < E\cdot p_{max}\), \[\text{Nota} = 1 + 3\cdot\frac{1}{Ex}\cdot\frac{p}{p_{max}}.\]
Mientras que si se obtiene un puntaje \(p \geq E \cdot p_{max}\), \[\text{Nota} = 4 + 3\cdot\frac{p - Ex \cdot p_{max}}{p_{max}\cdot ( 1- Ex)}.\]
¿Qué nota obtuvo usted si obtuvo 25 puntos en una prueba de 30 puntos como máximo bajo una exigencia del 80%?
¡Actividad de Cinco Minutos!
(para conocedores de funciones y condicionales) Construya una función que entregue la nota obtenida en una evaluación tras recibir como argumentos el puntaje obtenido, el puntaje total de la evaluación, y el porcentaje de exigencia.
Explore las escalas de notas bajo el 50%, 60%, y 70%.
Usando cat, concatene en una única frase el siguiente poema de Pablo Neruda:
Punto
No hay espacio más ancho que el dolor,
no hay universo como aquel que sangra.
En un único cat y con todo el poema en un único texto, use \n para que al imprimir el poema en la consola se haga un salto de línea tras la coma del poema. Observe qué ocurre si usa print para imprimir el mismo texto.
¡Actividad de Cinco Minutos!
En un único cat y con todo el poema en un único texto, use \n para que al imprimir el poema en la consola se haga un salto de línea tras cada salto incluido por el poeta.
Océano
Cuerpo más puro que una ola,
sal que lava la línea,
y el ave lúcida
volando sin raíces.
Creando Objetos en R
Definir cantidades que puedan ser operadas posteriormente en el código.
Sintaxis:
Nombre <- Elemento Almacenado como "Nombre"
FondosTotales <-2234031## Se gasto 120000 en impresiones## Se gastaron 120000 en renovacion de equipos## Se gastaron 30000 en chocmans## Ingresaron 944000 por pago de clientes## .## .## Otras operaciones importantes## .print(FondosTotales)
[1] -25900
Objeto FondosTotales recibió cambios (ficticios) y tiene nuevo valor.
Se puede usar = en vez de <- pero puede llevar a confusiones.
NombreFuncion <-function(Argumento1, Argumento2, ...){## No dar ningun argumento tambien es opcion.## Aqui dentro se escriben todo el procedimiento## que se desea ejecutar cuando NombreFuncion es llamada.## Si se desea que la funcion retorne un ## objeto tras su ejecucion:return(Objeto)## Tambien es opcion que no entregue nada.}
Considere la función Funcion(Argumento, X_Y, Z).
Suponga, para este caso, que para que la función funcione, los tres argumentos deben recibir valores numéricos.
Cualquiera de las siguientes opciones son sintaxis válidas en R:
Funcion(100, 200, 300)Funcion(Argumento =100, X_Y =200, Z =300)Funcion(Arg =100, X =200, Z =300)Funcion(A =100, 200, 300)
Ejemplos:
Función que imprime el poema de Neruda cuando es llamada.
Poema <-function(){cat("No hay espacio más ancho que el dolor, \nno hay universo como aquel que sangra.")}
Poema()
No hay espacio más ancho que el dolor,
no hay universo como aquel que sangra.
Ejemplos:
Función que transforma grados Celsius a Farenheit.
Construya una función que reciba de argumentos las notas de la Tarea 1 y 2 y entregue como salida el mensaje Promedio de Laboratorios = NOTA OBTENIDA.
Construya una funcion que reciba de argumentos las notas de los laboratorios 1, 2, 3, y 4, las tareas 1 y 2, y el examen, y que calcule la nota final del curso. La nota final debe entregarla junto a un mensaje acorde.
Muestre evidencia de que realizó el resto de actividades de esta clase.
Basta responder hasta aquí para haber completado la actividad bonificada.
. . .
Continúa….
¡Actividad Bonificada!
Escriba una función que tome como argumentos una nota y un porcentaje de exigencia, y que devuelva la nota ajustada a un nuevo porcentaje de exigencia, asumiendo que la nota original corresponde a un 50% de exigencia.
Escriba una función que reciba tantos argumentos como evaluaciones haya en el curso, además de un porcentaje de exigencia. La función deberá recalcular la nota final del curso ajustándola al porcentaje de exigencia indicado, asumiendo que las evaluaciones originales corresponden a un 50% de exigencia.
Estructura de Datos en R
Sabemos añadir un único elemento a un objeto
notaEstudiante1 <-5.4notaEstudiante2 <-6.0
Quisiéramos añadir múltiples elementos a un único objeto.
Vectores de Datos
Función c() (combine) para crear y guardar un vector:
a:b: crea secuencia de números enteros desde a hasta b.
1:100:5-10:-2-5:-8
seq(from, to, by, ...): crea secuencia numérica desde from hasta to dando saltos de según by.
seq(from =1, to =10, by =1)seq(from =1, to =100, by =10)seq(from =1, to =-10, by =-2)seq(from =1, to =100, length.out =15) # length.out en vez de by para solicitar largo de secuencia
Funciones útiles de R para crear vectores:
rep(x, times, length.out, each): repite el o los valores x dependiendo de si se entrega times, length.out, o each.
times: repite x un número times de veces.
rep(x =1, times =4)
[1] 1 1 1 1
rep(x =c(1,2), times =4)
[1] 1 2 1 2 1 2 1 2
rep(x, times, length.out, each):
each: repite cada elemento de x un número each de veces.
rep(x =1, each =4)
[1] 1 1 1 1
rep(x =c(1,2), each =4)
[1] 1 1 1 1 2 2 2 2
length.out: repite x hasta que vector sea de largo length.out.
rep(x =1, length.out =4)
[1] 1 1 1 1
rep(x =c(1,2), length.out =4)
[1] 1 2 1 2
Ayuda de R
help(funcion) - ?funcion
Estructura de Documentación de Ayuda
EPG3308: Computación Estadística
Clase 03: Estructura de Datos
Profesor: Hernán Robledo Araya (harobledo@uc.cl) Ayudante: Josefa Silva Muñoz (josefa.silva@alumni.uc.cl)
Primer Semestre - 2025
Hoy veremos:
Operaciones con Vectores
Matrices y Operaciones con Matrices
Listas y Operaciones con Matrices
Cuadros de Datos (Data Frames)
Lectura de Datos
1. Vectores de Datos
Función c() (combine) para crear y guardar un vector:
Nombre <- c(Elemento1, Elemen2, Elem3, ...)
Funciones: seq y rep.
Veremos:
Acceder a elementos
Funciones para vectores
Matemática Vectorizada
Cálculos Matemáticos
Acceso a elementos de vector con vector[posicion]:
Acceder a un único elemento:
Notas <-c(4.0, 4.5, 4.7, 5.2, 6.0, 7.0)Notas[1] # Primer elemento
[1] 4
Notas[2] # Segundo elemento
[1] 4.5
Acceder a múltiples elementos: vector de índices.
indices <-c(1,2)Notas[indices]
[1] 4.0 4.5
indices <-c(3,6)Notas[indices]
[1] 4.7 7.0
Acceso a elementos de vector con vector[posicion]:
Todos excepto un elemento: vector[-posicion]
Notas[-1] # Todos excepto primer elemento
[1] 4.5 4.7 5.2 6.0 7.0
Notas[-6] # Todos excepto sexto elemento
[1] 4.0 4.5 4.7 5.2 6.0
Acceder a todos excepto un subconjunto:
indices <-c(1,2)Notas[-indices] # Elementos 3, 4, 5 y 6
[1] 4.7 5.2 6.0 7.0
pares <-seq(2,6,2)Notas[pares]
[1] 4.5 5.2 7.0
Modificar o añadir elementos de un vector
vector[indices] <- vector2
vec <-c() # Vector vacíovec # Equivalente a hacer print(vec1)
NULL
vec[1] <-4.5vec
[1] 4.5
vec[5] <-6.0vec
[1] 4.5 NA NA NA 6.0
vec[2:4] <-c(5.0, 5.1, 5.2)vec
[1] 4.5 5.0 5.1 5.2 6.0
vec[c(1, 5, 8:9)] <-1# Reemplazar todo por valor 1vec
[1] 1.0 5.0 5.1 5.2 1.0 NA NA 1.0 1.0
Funciones útiles:
length(vector): entrega el numero de elementos contando NAs.
sort(vector): ordena los elementos del vector.
rank(vector): entrega el ranking de los elementos según su valor.
rev(vector): invierte el orden de los elementos del vector.
unique(vector): entrega un vector en que se eliminan los valores repetidos de vector.
table(vector): tabla de frecuencia de los elementos de vector.
Tip
Tip: Cuando necesiten hacer algo específico pregúntense:
¿existe una función que ya lo haga?
Matemática con Vectores:
Sumas, restas, productos, divisiones, potencias y otras operaciones sí funcionan entre vectores.
Operación entre Vector y Escalar
vec <-c(1, 2, 4)vec^2
[1] 1 4 16
Operación entre Escalar y Vector
vec <-c(1, 2, 4)5^vec
[1] 5 25 625
Operación entre Vector y Vector
vec1 <-c(1, 2, 3); vec2 <-c(0, 1, 2)vec1 ^ vec2
[1] 1 2 9
Esta cualidad de R es llamada Cálculos Vectorizados.
Más eficientes que recorrer cada elemento, aplicar la operación deseada, y continuar con el siguiente elemento.
mivector <-c(4.8, 5.3, 3.8, 6.1, 3.9, 4.4, 2.6, 1.8, 0.4, 0.5)## Funcion que eleva al cuadrado cada elemento de un vectorvectoralcuadrado <-function(){ resultado <-c()for(i in1:10){ resultado[i] <- mivector[i]^2 }return(resultado)}## Comparacion en nanosegundos de tiempos de computo entre## calculo vectorizado y escalarmicrobenchmark::microbenchmark(mivector^2, vectoralcuadrado(), times =1000)
Reciclaje de elementos:
Cuando se aplica una operación entre vectores de distintos tamaños, R comienza a reciclar elementos del vector más corto.
vec1 <-1:20# Vector de largo 20vec2 <-rep(c(0,1), times =5) # Vector de largo 10length(vec1*vec2)
[1] 20
vec1*vec2
[1] 0 2 0 4 0 6 0 8 0 10 0 12 0 14 0 16 0 18 0 20
Advertencia
Preferir no reciclar. Operar con vectores de igual tamaño.
Matemática con Vectores
sum(vector): Calcula la suma de todos los elementos.
prod(vector): Calcula el producto de todos los elementos.
mean(vector): Calcula el promedio entre los elementos.
median(vector): Encuentra la mediana de los elementos.
quartile(vector, prob): entrega el cuartil que acumula prob del vector dado.
¡Actividad de Diez Minutos!
El archivo DataC03.RData se carga con el comando load("DataC03.RData") y contiene tres vectores con información de una muestra de estudiantes y sus puntajes en una prueba de competencias matemáticas. Los vectores tienen los nombres edad, comuna y puntuacion.
Corrija el registro de la posición 97 en edad. Cree un nuevo cetor llamado edad2. ¿Habrá otro valor mal codificado?
Siguiendo las recomendaciones de asignaciones de nombres a objetos, cree tres vectores con las edades de los estudiantes y tres vectores con las puntuaciones, agrupados por comuna.
¡Actividad de Diez Minutos!
Calcule estadísticas descriptivas (promedio, mediana, desviación estándar, mínimo y máximo) de las edades de los estudiantes agrupadas por comuna.
Calcule estadísticas descriptivas (promedio, mediana, desviación estándar, mínimo y máximo) de las puntuaciones obtenidas por los estudiantes agrupadas por comuna.
2. Matrices
Arreglo bidimensional (tienen filas y columnas) de datos.
Utilice los datos del archivo Data03.RData para hacer lo siguiente:
Crear una matriz de dos columnas usando la función matrix que contenga los datos de los vectores edad y puntuacion. Coloque nombres adecuados a las columnas de la matriz.
Crear una matriz de tres columnas usando la función cbind que contenga los datos de los vectores edad, comuna, y puntuacion. Coloque nombres adecuados a las columnas de la matriz. ¿Qué se observa en la matriz resultante?
Matemática elemental con matrices
Igual que con vectores, se pueden aplicar las operaciones matemáticas elementales entre matrices.
A <-matrix(c(1,0,1,1), nrow =2)B <-matrix(c(-2,-1,0,1), nrow =2)vec <-c(1,2)1+ A2*AA^2A + vec # Aplica operacion a cada columna de AA * vecA+B
Más operaciones en la Clase 08: Álgebra Lineal
Funciones por columnas o filas con matrices
colSums(matriz): Sumar datos por cada columna.
rowSums(matriz): Sumar datos por fila columna.
colMeans(matriz): Promediar datos por cada columna.
rowMeans(matriz): Promediar datos por cada fila.
apply: Aplicar una función cualquier por fila o columnas.
apply(matriz, fila_o_columna, funcion)
Funciones por columnas o filas con matrices
apply(matriz, fila_o_columna, funcion_a_aplicar)
A <-matrix(c(1,0,1,1,-1,2), ncol =2) apply(A, MARGIN =1, # 1 = aplicar operacion por filasFUN = mean) # Equivalente a hacer rowMeans
[1] 1.0 -0.5 1.5
apply(A, MARGIN =2, # 2 = aplicar operacion por columnasFUN = sd) # Calcular desviacion estandar por columnas
[1] 0.5773503 1.5275252
apply(A, MARGIN =2, # 2 = aplicar operacion por columnasFUN = sd) # Calcular desviacion estandar por columnas
[1] 0.5773503 1.5275252
Acceder a elementos de matrices
matriz[filas, columnas]
Misma idea que con vectores.
Ejemplos:
A <-matrix(c(1,0,1,1,-1,2), ncol =2) A[1,1]A[2,1]A[1:3, 1]A[c(1,3), c(1,2)]A[1,] # Primera filaA[,2] # Segunda columnaA[-1,] # Todo menos primera filaA[-2,-3] # Todo menos segunda fila y segunda columna
Funciones útiles para matrices
dim(matriz): entrega el número de filas y columnas de una matriz.
nrow(matriz) y ncol(matriz): lo mismo que la función anterior.
diag(matriz): entrega un vector con los elementos ubicados en la diagonal de la matriz.
¡Actividad Bonificada!
El archivo Clase03_notas.RData contiene una matriz con las notas de los estudiantes de cierto curso.
Calcule el promedio de las evaluaciones para cada estudiante.
Calcule para cada evaluación el promedio de notas.
Calcule mínimo, máximo, y desviación estándar de las notas de cada evaluación.
Muestre evidencia de haber realizado el resto de actividades de la clase.
Listas
Colección de elementos de distinta naturaleza (numérico, texto, tablas, etc.)
Crear lista con list()
Acceder a los elementos con Lista[[ elemento ]]
Si elementos tienen nombres, pueden ser llamados con Lista$Nombre.
all(cond1, cond2, ...): entrega TRUE si todas las condiciones se cumplen y FALSE si no.
any(cond1, cond2, ...): entrega TRUE si al menos una de las condiciones se cumplen y FALSE si no.
all.equal(x,y): evalúa si dos objetos son idénticos o no (incluye grado de tolerancia).
Actidad de Práctica
Cargue en R la tabla del archivo pokemon.csv.
Filtre la tabla según las filas que cumplan type1 == "water" usando tabla[tabla$type1 == "water,].
Filtre la tabla según las filas que cumplan type1 == "fire".
Filtre la tabla según las filas que cumplan type1 == "fire" y type2 == "flying".
Filtre la tabla según las filas que cumplan type1 == "fire" o type1 == "water".
Control de Flujo
Considere la siguiente situación:
Si un estudiante viene de la comuna de San Joaquín, recibirá una prueba de 20 preguntas.
Si un estudiante viene de otra comuna, recibirá una prueba de 30 preguntas.
Queremos una función que de el número de preguntas según la comuna.
NPreguntas <-function(comuna){# Si comuna es "San Joaquin", entonces nitems <-20return(nitems)# Si comuna NO es "San Joaquin", entonces nitems <-30return(nitems)}
Control de Flujo: if-else
if(condicion a evaluar){
# Código evaluado si se cumple condición
}else{
# Código evaluado si NO se cumple condición
}
NotaEPG3308 <-function(p, pMax, Ex){if(p < Ex * pMax){ Nota <-1+3*p/(Ex*pMax)return( round(Nota,1) ) }else{ # En caso contrario, p >= Ex * pMax Nota <-4+3*(p - Ex*pMax)/(pMax*(1- Ex))return( round(Nota,1) ) }}
NotaEPG3308(p =15, pMax =30, Ex =0.5)
[1] 4
NotaEPG3308(p =15, pMax =30, Ex =0.65)
[1] 3.3
Observaciones
Dentro de la condición del if puede venir cualquier operación lógica de interés.
if(comuna == "A" & edad > 50 & ptje == 10 & ...)
Si se desean ejecutar más de dos casos usar else if():
Resuelva cada caso utilizando procedimientos vectorizados y utilizando control de flujo (if-else y/o for)
Construya una función que reciba un vector de notas e imprima un mensaje indicando si alguien obtuvo una nota 7.0 o no.
Usando el archivo Clase03_notas.R y las notas calculadas previamente, escriba un código que recorra el vector de notas e imprima un mensaje para cada una, según estos casos:
Si Nota < 4.0 \(\rightarrow\) “No se exime de examen”.
Si Nota está entre 4.0 y 6.0 \(\rightarrow\) “Posible eximición examen”.
Si Nota > 6.0 4.0 \(\rightarrow\) “Eximido de examen”.
EPG3308: Computación Estadística
Clase 05: Herramientas Gráficas
Profesor: Hernán Robledo Araya (harobledo@uc.cl) Ayudante: Josefa Silva Muñoz (josefa.silva@alumni.uc.cl)
Primer Semestre - 2025
Gráficos en R Base
Análisis de Estadísticas descriptivas:
Concentraciones de Tratamientos Biológicos bajo 4 Experimentos
Experimento
Media
Desv. estándar
Mínimo
Máximo
Exp 1
0.20
0.40
0.00
1.00
Exp 2
0.40
0.05
0.10
0.70
Exp 3
0.60
0.08
0.20
1.00
Exp 4
0.80
0.25
0.30
1.00
¿Qué podemos decir de estos resultados?
¿Por qué usar graficos para visualizar información?
Cómo NO graficarán los alumnos de este curso:
🤨🤨🤨
Cómo sí graficarán los alumnos de este curso:
🧐🧐😇😇
Consideraciones
Dedicar tiempo a la confección de gráficos.
Presentar gráficos en base a una historia que se desea contar.
¿Qué quiero decir con este gráfico?
No todo gráfico es interesante de ver.
No sobrecargar los gráficos.
Reflexionar: ¿de cuántas maneras puedo presentar los mismos resultados?
R puede no ser la mejor herramienta para hacer un gráfico.
Veremos:
Histogramas
Gráficos de Densidad
Gráficos de Dispersión
Gráficos de Línea
Diagrama de Caja
Diagrama de Torta
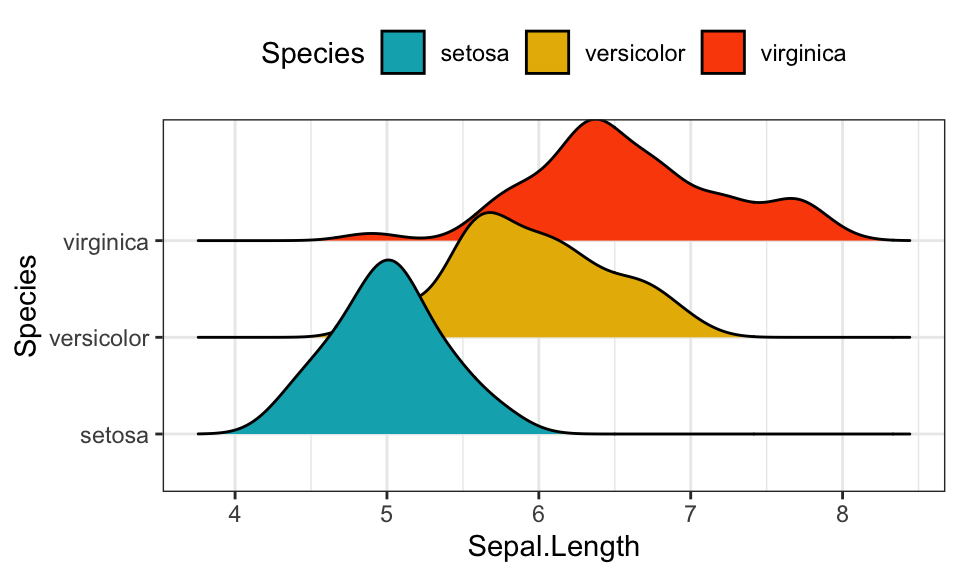
¿Cómo estudiamos la distribución de una variable?
Distribución de una variable numérica
Con qué forma y dónde se distribuyen los valores observados de una variable.
¿Centro de los datos?
¿Dispersión en torno al centro?
Simétricos o asimétricos en torno a un centro?
¿Unimodal o multimodal?
¿Datos extremos?
Histogramas
Histogramas con hist(x)
Advertencia
Imagen sensible (disculpas correspondientes)
load("Clase05_Datos.RData")hist(datos[,1])
hist(datos[,1],main ="main asigna un titulo al grafico",xlab ="xlab modifica etiqueta del Eje X",ylab ="ylab modifica etiqueta del Eje Y",xlim =c(-4,4), # Modificar rango de eje Xylim =c(0,120), # Modificar rango de eje y.freq =TRUE, # ¿Frecuencia absoluta (TRUE) o relativa/densidad (FALSE)?col ="lightblue2", # Color de rellenoborder ="lightblue4", # Color de bordelas =1, # Etiquetas eje Y rotadasbreaks =15# Numero de barras )
Superponer dos histogramas con add = TRUE.
hist(datos[,1], col ="red3", xlim =c(-5,10), main ="Superponer histogramas", xlab ="eje X", ylab ="Frecuencia Relativa")hist(datos[,2], add =TRUE, col ="orange2")
En estadística suponemos que datos surgen de un modelo.
¿Graficar histograma suavizado que se parezca a la teoría?
Histograma suavizado:density(x)
par(cex =1.4) # Aumenta todo el tamaño del graficohist(datos[,1], main ="Densidad de Kernel con density(x)", xlab ="", ylab ="", xlim =c(-4,4), freq = F, col ="lightblue2", border ="lightblue4", las =1, breaks =15 )lines(density(datos[,1]), col ="blue2",lwd =2, # Linea de ancho 2lty =2# Linea punteada )
Histograma suavizado:density(x)
Útiles cuando se desea simplificar el gráfico. Requiere comprender una densidad.
par(cex =1.5)boxplot(datos[,1], ylim =c(-4,4),main ="Titulo del Diagrama de Caja",horizontal =TRUE,col ="lightblue2", # Rellenoborder ="lightblue4", # Borde de la cajaboxwex =1.2, # Ancho de la cajapch =19); grid()
Diagramas de caja según categorías con sintaxis y ~ x
boxplot(Sepal.Length ~ Species, data = iris, las =1,xlab ="Especie", ylab ="Largo del Sepal", col =2:4, pch =19)grid()
Histograma, gráfico de densidad, y boxplot permiten analizar o comparar distribuciones.
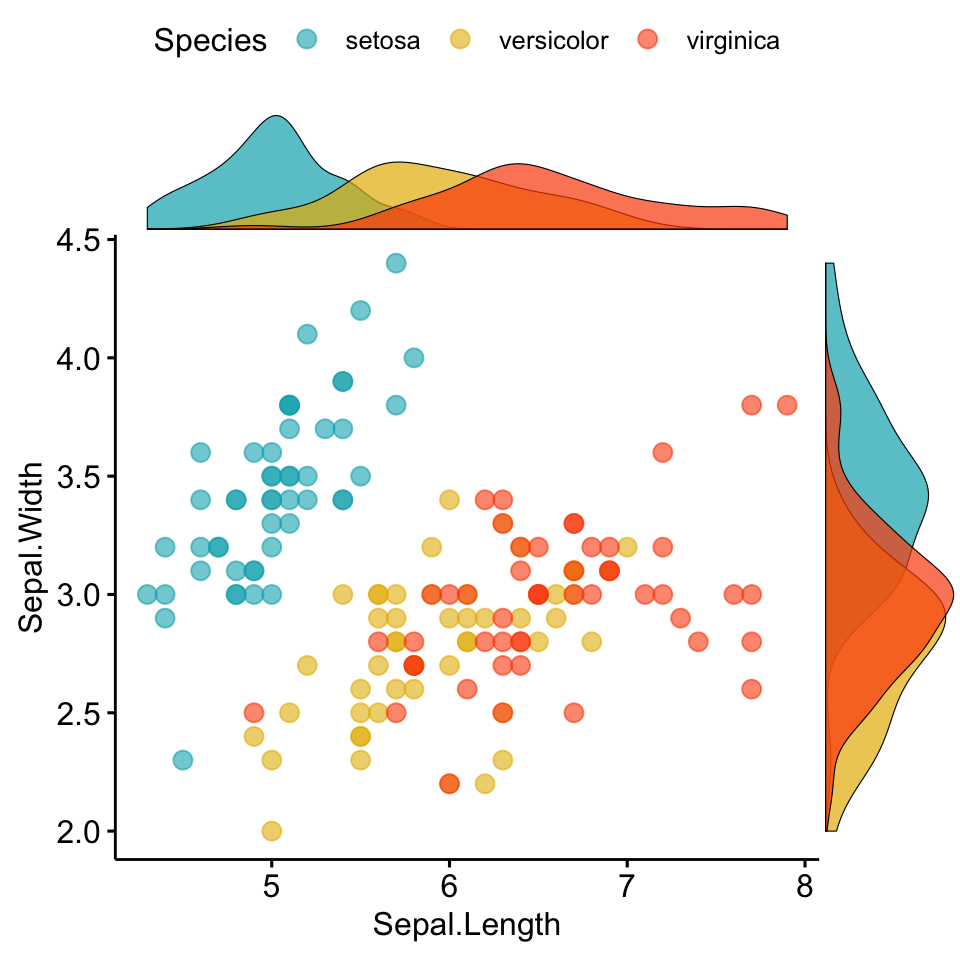
Usaremos gráficos de dispersión para comparar relación entre dos variables:
¿Peso corporal predice la presión arterial?
¿A mayor cantidad de estudio, mejor rendimiento?
¿Evoluciona una variable en función del tiempo?
Gráfico de Dispersión:plot(x, y)
Gráfico de Dispersión:plot(x, y)
load(file ="Clase05_Datos3.RData")plot(y1 ~ y2, data = datos3)
🤢🤢🤢💀💀💀
par(cex =1.2)plot(y2 ~ y1, data = datos3,main ="Relacion entre variable y1 y y2", xlab ="Variable y1", ylab ="Variable y2",type ="p",col ="red3",pch =19,las =1)grid(col =rgb(0.2,0.2,0.2,0.5))
Gráfico de líneas con type = "l"
par(cex =1.2)plot(y1 ~ tiempo, data = datos3,main ="Serie de Tiempo", xlab ="tiempo", ylab ="Variable y1",type ="l",col ="red3",pch =19,las =1)grid(col =rgb(0.2,0.2,0.2,0.5))
Apartado técnico de gráficos en R.
Crear un gráfico es abrir un dispositivo gráfico.
Funciones de alto nivel como plot() abren el dispositivo.
Funciones de bajo nivel: permiten añadir elementos al dispostivo abierto. No sirven por si solas.
Volver a configuración por defecto cerrando el dispositivo gráfico con dev.off()
Graficar funciones matemáticas:curve()
Graficar la función \(f(x|k,v,\dots)\) en \(a < x < b\).
Se evalúa en \(x\) y tiene posibles parámetros \(a\), \(b\), \(\dots\) que la modifican.
Sintaxis:
curve(f(x, k, v), from = a, to = b)
Ejemplo: distribución Normal Estándar
f <-function(x) exp(-x^2/2)/sqrt(2*pi)curve(f(x), from =-3, to =3, las =1, main ="Distribucion Normal Estandar", lwd =2)
Ejemplo: distribución Gamma\((k,v)\):
f <-function(x, k, v) v^k/gamma(k)*x^(k-1)*exp(-v*x)curve(f(x,k =3, v =0.5), from =0, to =20, las =1, main ="Distribucion Gamma", lwd =2)
Ejemplo: graficar funciones que ya vienen en R
curve(exp(x), from =-3, to =3, lwd =2)curve(sin(x), from =-10, to =10, lwd =2)curve(dnorm(x,0,4), from =-10, to =10, lwd =2)curve(pexp(x,1), from =0, to =10, lwd =2)curve(ppois(x,4), from =0, 10)curve(pbinom(x,size=20,prob=0.2), from =0, 10)
frutas <-c("Manzana", "Plátano", "Naranja", "Fresa", "Uva")cantidades <-c(25, 15, 20, 10, 30)pie(cantidades, labels = frutas,main ="Preferencia por tipo de fruta",col =rainbow(length(frutas)))barplot(cantidades,names.arg = frutas,main ="Preferencia por tipo de fruta",ylab ="Cantidad de personas",col ="skyblue",border ="white")
Demostración real de cómo hacer un gráfico complejo:
Extensiones de ggplot2: https://exts.ggplot2.tidyverse.org/gallery/
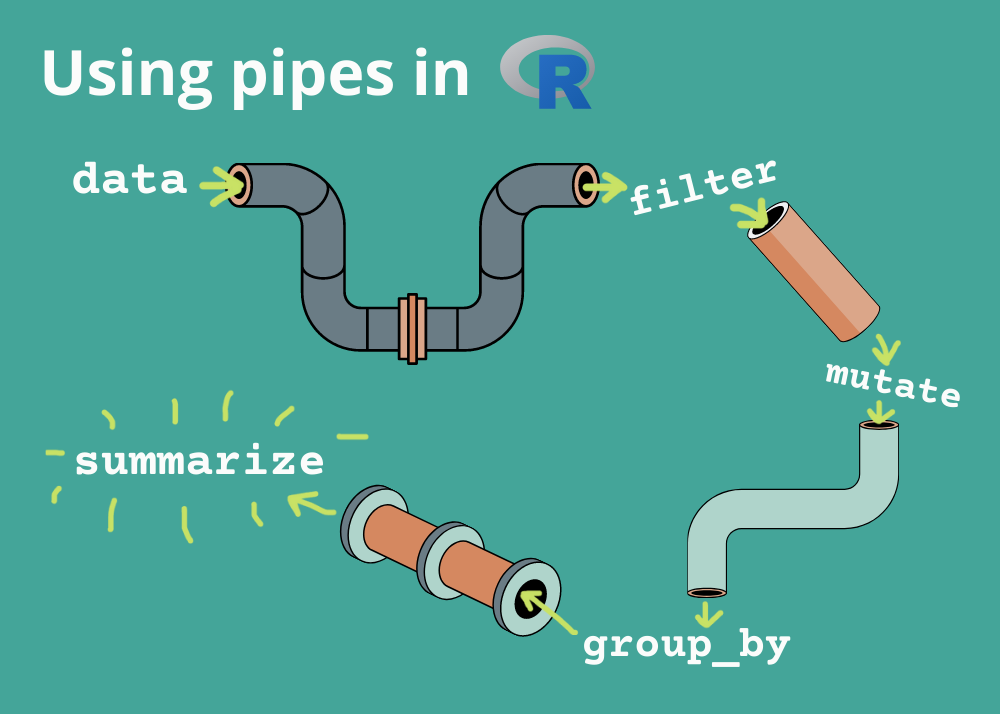
ggplot2 es una librería (o paquete) de R
Librería: conjunto de funciones para objetivo particular.
Librería dplyr: funciones para manipular datos.
Librería moments: trae funciones para calcular estadísticas descriptivas
Instalar librería:
install.packages("NOMBRE DE LIBRERIA")
Cargar la librería:
library(NOMBRE DE LIBRERIA)
ggplot2
install.packages("ggplot2")library(ggplot2)
Sintaxis basada en la composición de capas.
Se indica qué se quiere visualizar (y no cómo)
ggplot(Datos) +aes(Variables a Graficar) +geom_TipodeGrafico() + Adiciones_Extras_al_grafico.
Distintas capas son conectadas con +
Ejemplo:
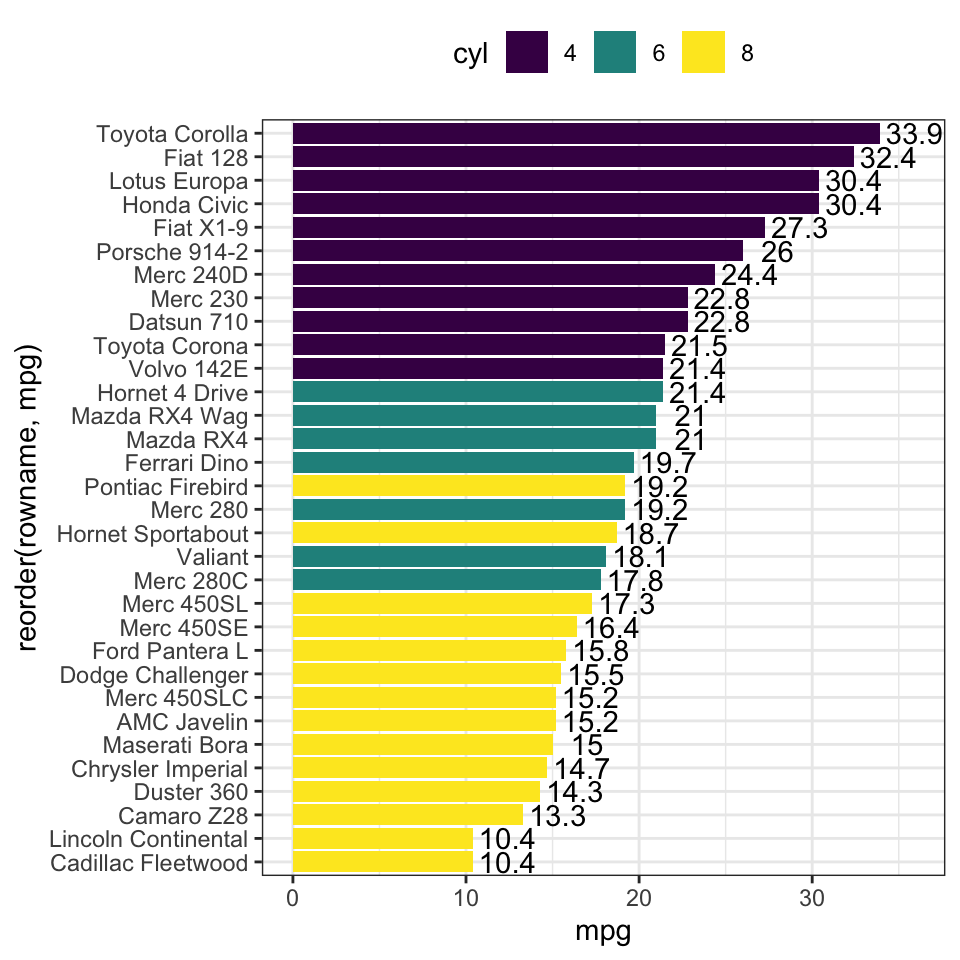
library(ggplot2)ggplot(data = mtcars) +# 1. Especificar datosaes(x = wt, y = mpg, color =factor(cyl)) +# 2. "Mapear" variables geom_point(size =3) +# 3. Graficar puntoslabs(title ="Consumo vs Peso del Vehículo", # 4. Etiquetasx ="Peso (wt)", y ="Consumo (mpg)") +theme_minimal() # 5. Aplicacion de un tema
Elementos de ggplot:
aes(x,y): “aesthetics mappings” o atributos estéticos. Especificar cómo variables se conectan con elementos visuales (estéticas) del gráfico.
+aes(x = Edad, # variable Edad en eje xy = Ingresos, # variable Ingresos en eje ycolor = Genero, # asignar colores segun Generoshape = Comuna # graficar puntos distintos segun Comuna )
geom_X(): especificar la geometría del gráfico, es decir, la forma gráfica para visualizar los datos.
geom_point() # Gráfico de Dispersióngeom_bar() # Gráfico de Barrasgeom_histogram() # Histogramas
ggplot(ENS) +aes(y = Peso, x = Sexo, fill = Sexo) +geom_violin()
Ejemplos
Gráfico de Dispersión
ggplot(ENS) +aes(x = Peso, y = Altura) +geom_point()
Ejemplos
Gráfico de Dispersión
ggplot(ENS) +aes(x = Peso, y = Altura, color = Sexo) +geom_point()
Ejemplos
Gráfico de Caja
ggplot(ENS) +aes(x = Peso, y = Altura, color = Sexo) +geom_boxplot(fill ="grey95")
Ejemplos
Gráfico de Caja
ggplot(ENS) +aes(x = Peso, y = Altura, color = Sexo) +geom_boxplot(fill ="grey95") +coord_flip() +# Rota coordenadaslabs(title ="Mi primer Grafico de Caja en ggplot2",x ="Peso en Kg",y ="Altura en cm") +theme_minimal()
El número de condicionamiento, \(\kappa\), de una matriz indica la estabilidad de las soluciones del sistema \(Ax = b\).
A <-matrix(c(2,1,2,2), ncol =2)kappa(A)
[1] 7.692308
A <-matrix(c(2,1,4,2.00001), ncol =2)kappa(A)
[1] 1500003
¡Actividad Bonificada!
Verifique si las siguientes matrices \(A\) son invertibles y , en caso de serlos, resuelva el sistema lineal correspondientes al vector \(b\) indicado.
Los datos airquality poseen mediciones diarias de la calidad del aire en Nueva York durante 1973, incluyendo concentración de ozono, temperatura, radiación solar y velocidad del viento.
Se busca explicar la variable Ozone en función de las otras tres variables disponibles: Solar.R, Wind y Temp.
AQ <-na.omit(airquality) # Omitir valores faltantes
Se busca encontrar el valor \(x^* \in \mathbb{R}^n\) tal que \(f(x^*)\) sea un máximo o un mínimo.
Procedimiento para el caso univariado
Para una función continua y dos veces diferenciable \(f: \mathbb{R} \to \mathbb{R}\)
Obtener analíticamente \(f'(x)\) y \(f''(x)\).
Encontrar el valor \(x^*\) tal que \(f'(x^*) = 0\).
Evaluar \(f''(x^*)\).
Si \(f''(x^*) > 0\), entonces \(f(x^*)\) es un mínimo.
Si \(f''(x^*) < 0\), entonces \(f(x^*)\) es un máximo.
Si \(f''(x^*) = 0\), no se puede concluir.
Soluciones computacionales aproximadas
Función optimize para encontrar el máximo o mínimo de una función en un intervalo.
Ejemplo: encontrar \(x^*\) que minimice la suma cuadrática
\[f(x) = \sum_{i = 1}^n (y_i - x)^2\]
y <- iris$Sepal.Lengthf <-function(x) sum( (y - x)^2 ) ## Minimizar la suma cuadraticaRes <-optimize(f = f,interval =c(-100, 100),maximum =FALSE# Para encontrar un minimo.)Res$minimum # El valor x* de f(x) donde se logra el minimoRes$objective # f(x) evaluado en el x* que lo minimiza
Procedimiento para el caso multivariado
Sea \(f: \mathbb{R}^n \to \mathbb{R}\) una función continua y dos veces diferenciable.
varf <-function(x, k, v) (x -0.8)^2* ( (v^k/gamma(k)) *(x^(k-1))*exp(-v*x) )integrate(varf, lower =0, upper =Inf, k =4, v =5)
0.16 with absolute error < 6.4e-06
Actividad Bonificada
Calcule la probabilidad de que una variable aleatoria que sigue una distribución normal de media 9 y varianza 1 sea menor a 10, \(\operatorname{Pr}(X < 10)\).
# Tablas baseTab1 <-tibble(ID =c(1, 2, 4, 5),X =c("%", "%", "%", "%"))Tab2 <-tibble(ID =c(1, 3, 4, 6),Y =c("%", "%", "%", "%"))Tab1 %>%left_join(Tab2, by ="ID")Tab1 %>%right_join(Tab2, by ="ID")Tab1 %>%inner_join(Tab2, by ="ID")Tab1 %>%full_join(Tab2, by ="ID")
Actividad
Considere la base de datos starwars del paquete dplyr.
Seleccione las columnas name, species, height, mass, gender.
Filtre por los personajes humanos que miden más de 180 cm.
Ordene los personajes por peso (mass) de mayor a menor.
Añada una nueva columna a la tabla que corresponda al IMC (masa/(altura en cm)^2).
Actividad
Agrupando por especie, calcule el número de personajes, la altura promedio, y el peso promedio. mass
Considere ahora la tabla flights y airlines que contienen información sobre todos los vuelos que salieron desde Nueva York en 2013. Obtenga una nueva tabla cuya primera columna corresponda al nombre completo de la aerolínea, la segunda indique el número total de vuelos realizados por dicha aerolínea, la tercera muestre el tiempo promedio en el aire de estos vuelos (air_time), y la cuarta indique la distancia promedio entre aeropuertos (distance).
Librerías útiles fuera de tidyverse:
data.table: versión rápida y eficiente de data.frame, ideal para filtrar, agrupar y transformar grandes conjuntos de datos.
parallel: permite ejecutar tareas en varios núcleos del procesador para acelerar operaciones intensivas.
lubridate: simplifica el manejo de fechas y horas, permitiendo extraer componentes y realizar cálculos fácilmente.
data.table
Es una versión optimizada de data.frame.
Pensada para trabajar con grandes volúmenes de datos de forma rápida y eficiente.
Acelerar tareas intensivas como simulaciones, cálculos repetitivos o procesamiento de grandes volúmenes de datos.
Funciona creando procesos hijos (workers) que ejecutan tareas en paralelo.
Importante: cada proceso es una sesión de R abierta. Controlar la RAM.
parallel
Funciones principales
detectCores(): identifica cuántos núcleos tiene tu equipo.
makeCluster(): crea un clúster de procesos.
parLapply(): aplica funciones en paralelo sobre un clúster.
parallel
library(parallel)# Número de núcleos disponiblesnucleos <-detectCores()# Crear un clúster con 4 núcleoscl <-makeCluster(4)# Función a aplicarcuadrado <-function(x) x^2# Aplicar en paralelo sobre 1:10parLapply(cl, 1:10, cuadrado)# Cerrar el clústerstopCluster(cl)
lubridate
Librería para trabajar con fechas y horas en R de manera simple y legible.
Permite:
Parsear fechas en texto: ymd(), mdy(), dmy(), etc.
Extraer componentes: year(), month(), day(), hour(), etc.
Hacer operaciones: sumar días, calcular diferencias, redondear tiempos.
Hace el código más claro que trabajar con as.Date() o POSIXct manualmente.
lubridate
library(lubridate)# Crear una fecha desde textofecha <-ymd("2023-10-01")# Extraer componentesyear(fecha) # 2023month(fecha) # 10wday(fecha, label =TRUE) # "Sun"# Sumar díasfecha +days(5) # "2023-10-06"# Fechas desde texto con distintos formatosdmy("12-04-2023") # 2023-04-12mdy("04-12-2023") # 2023-04-12
Próxima clase:
EPG3308: Computación Estadística
Clase 09: Shiny
Profesor: Hernán Robledo Araya (harobledo@uc.cl) Ayudante: Josefa Silva Muñoz (josefa.silva@alumni.uc.cl)
Primer Semestre - 2025
Paquete para construir aplicaciones web interactivas.
Ideal para:
Visualización de datos
Dashboards
Herramientas docentes
¿Por qué usar Shiny?
Facilita la interacción con estadística sin necesidad de programar.
library(shiny)ui <-TipoDePagina(## Se controla que elementos verá el usuario y con cuales## podrá interactuar.)server <-function(input ,output){# Es el cerebro de la aplicacion.# Aqui se hacen todos los cálculos de acuerdo a los inputs recibidos. }# Inicializacion de la AppshinyApp(ui = ui, server = server)
UI: Interfaz de Usuario
ui <- fluidPage(): página que se adopta al tamaño de la pantalla.
ui <- navbarPage(): página con pestañas para múltiples secciones.
ui <- dashboard(): interfaz tipo dashboard.
UI: Interfaz de Usuario
library(shiny)ui <-fluidPage( # Tipo de Pagina: Pagina FluidasidebarLayout( # Estructura Interna: Barra Lateral y Panel PrincipalsidebarPanel( # Barra Lateral# Todo lo que vaya en la barra lateral ),mainPanel( # Panel Principal# Todo lo que vaya en el panel principal ) ))server <-function(input, output) {} # Server vacioshinyApp(ui,server)
UI: Interfaz de Usuario
library(shiny)ui <-navbarPage("Mi App",tabPanel("Inicio"),tabPanel("Análisis"))server <-function(input, output) {} # Server vacioshinyApp(ui,server)
Menús de Interacción del Usuario
numericInput(): cuadro para ingresar un número.
textInput(): cuadro para ingresar texto.
selectInput(): menú para selección múltiple.
sliderInput(): barra para seleccionar un número de un rango.
dateInput(): cuadro para ingresar una fecha.
fileInput(): menú para adjuntar un archivo.
Menús de Interacción del Usuario
library(shiny)ui <-fluidPage(sidebarLayout( sidebarPanel( numericInput(inputId ="inp1", label ="Ingrese Valor", value =5, min =1, max =10),textInput(inputId ="inp2", label ="Ingrese Texto"),selectInput(inputId ="inp3", label ="Seleccione opción.",choices =c("A", "B", "C"), multiple =FALSE),sliderInput(inputId ="inp4", label ="Seleccione un número",min =1, max =10, value =5) ),mainPanel( ) ))server <-function(input, output) {} # Server vacioshinyApp(ui,server)
server
server trae cálculos que se ejecutan al iniciar la app.
Los datos generados en UI llegan al server a través de la lista input.
Cada xxxxxInput tiene un inputId que define objeto.
numericInput(inputId ="numero", ...)textInput(inputId ="texto", ...)server <-function(input, output){ input$numero # para acceder a input de numericInput input$texto # para acceder a input de textInput}
server
Guardar en output elementos a imprimir en UI.
Como input, output también se comporta como una lista
server <-function(input, output){ output$ImprNum <-paste0("El numero seleccionado es ", input$numero)}
Especificar en UI cómo imprimir output.
ui <-fluidPage(textOutput(outputId ="ImprNum"))
server
Los valores generados por xxxxxInput son denominados Valores Reactivos.
Valores Reactivos: almacenan un valor que puede cambiar en el tiempo.
Llamadas de input$Objeto en server deben estar dentro de Entorno Reactivo.
output$ImprNum <-reactive({ <<------paste0("El numero seleccionado es ", input$numero)})
Código completo:
library(shiny)ui <-fluidPage(### Inputs:numericInput(inputId ="Numero", label ="Ingrese un número", value =1)### Outputs:textOutput(outputId ="ImprNum"))server <-function(input, output){ output$ImprNum <-reactive({paste0("El numero seleccionado es ", input$Numero) })}shinyApp(ui, server)
Entornos Reactivos
reactive(): encapsula código que depende de input y devuelve un resultado reactivo.
Sólo se ejecuta cuando es necesario.
No permite generar efectos visibles en UI.
Numero <-reactive({ input$Numero})
Entornos Reactivos
observe(): observador que permite generar efectos visibles en UI.
Se ejecuta cuando cambia alguna de sus dependencias.
No devuelve valor como reactive().
observe({print(input$nombre)})
Entornos Reactivos
observeEvent(): observador que se ejecuta cuando ocurre un evento específico.
server <-function(input, output){ output$Tabla <-renderTable({head(iris) }) output$Grafico <-renderPlot({hist(iris$Sepal.Length) })}
renderTable y renderPlot son reactivos.
Visualización de Outputs
En UI debe configurarse cómo imprimir Grafico y Tabla.
ui <-fluidPage(tableOutput(outputId ="Tabla") # Nombre de objeto creado en server (output$Tabla)plotOutput(outputId ="Grafico") # Nombre de objeto creado en server (output$Grafico))
Código completo (incorpora botón para imprimir resultados):
library(shiny)ui <-fluidPage(# InputactionButton(inputId ="PresionaBoton",label ="¿Mostrar Tabla y Gráfico?"),# OutputtableOutput(outputId ="Tabla"), # Nombre de objeto en outputplotOutput(outputId ="Grafico") # Nombre de objeto en output)server <-function(input, output) {observeEvent(input$PresionaBoton, { # Si se presiona boton se imprimen resultados output$Tabla <-renderTable({head(iris) }) output$Grafico <-renderPlot({hist(iris$Sepal.Length) }) })}shinyApp(ui, server)
Visto hasta ahora:
Estructura de Shiny App: UI + server.
Distintos tipos de UI.
Menús de Interacción - xxxxInput()
Uso de input y generación de output en server.
Valores y Entornos Reactivos.
Visualización de output en UI:
renderTable y renderPlot en server.
tableOutput y plotOutput en UI.
Actividad 1
Sin ejecutar la app, identifiquemos cómo esta interactua con usuario, qué inputs genera, cómo los procesa, qué outputs genera, y cuales imprime.
library(shiny)ui <-bootstrapPage(selectInput(inputId ="n_barras",label ="Número de barras en el histograma (aproximado):",choices =c(10, 20, 35, 50),selected =20),checkboxInput(inputId ="mostrar_obs",label =strong("Mostrar observaciones individuales"),value =FALSE),checkboxInput(inputId ="mostrar_densidad",label =strong("Mostrar estimación de densidad"),value =FALSE),plotOutput(outputId ="grafico_principal", height ="300px"),conditionalPanel(condition ="input.mostrar_densidad == true",sliderInput(inputId ="ajuste_bw",label ="Ajuste de ancho de banda:",min =0.2, max =2, value =1, step =0.2) ))server <-function(input, output) { output$grafico_principal <-renderPlot({hist(faithful$eruptions,probability =TRUE,breaks =as.numeric(input$n_bins),xlab ="Duración (minutos)",main ="Duración de erupciones del géiser")if (input$mostrar_obs) {rug(faithful$eruptions) }if (input$mostrar_densidad) { dens <-density(faithful$eruptions,adjust = input$ajuste_bw)lines(dens, col ="blue") } })}shinyApp(ui, server)
Actividad 2
Considere los datos iris sin la columna species. Diseñe una aplicación que haga lo siguiente:
Usando selectInput permita al usuario seleccionar una variable.
Usando selectInput permita al usuario seleccionar una segunda variable.
Con las dos variables seleccionadas anteriormente, imprimir un gráfico de dispersión. Ayuda: acceda a las variables usando tabla[[input$variable1]].
Usando actionButton, permitir al usuario decidir si desea imprimir las primeras doce filas de una tabla generada con las dos variables seleccionadas anteriormente.




































 Fuente: J. Pumarino
Fuente: J. Pumarino